Intro
When I was first introduced to the concept of parallel work, I was told the following explanation:
You have publishers that publish tasks, subscribers that consume messages, and a broker mechanism that is responsible for receiving the tasks from the publishers and sending them to subscribers that will actually perform the tasks, optionally returning an answer to the publishers.
This is called work queues, as illustrated here (one publisher and many consumers, from RabbitMQ’s official docs):
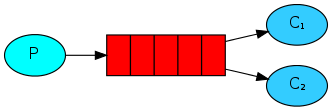
A common implementation of this configuration is done with celery for pub/sub and RabbitMQ for the broker. From now on, I’m going to talk about this configuration in particular.
It is also recommended that you have a basic understanding of queueing with RabbitMQ and celery from this point forward.
Real World Catastrophe
While this sounds great in theory, in practice there are many potential points of failure when deploying such a system.
One of the most common points of failure is data safety with regard to broker downtime.
The equation is simple:
- If we have only one node, and it is down (whether it may be for a brief power loss, a network error, or many other cases), then we have no way of sending and receiving messages.
- Even with multiple nodes (for multiple exchanges and bindings), the actual queue resides on a single node, so if the node is down, the queue is down.
Trust me—if you’re writing a microservice that handles important work, this is not good for uptime! 🥺
Minimizing Dependencies
Enter RabbitMQ’s Mirrored Queues.
Up until recently, this was the default way of having a cluster of RabbitMQ nodes operate even when nodes go down. Yet, quoting from RabbitMQ’s documentation on Quorum Queues:
Classic mirrored queues in RabbitMQ have technical limitations that makes it difficult to provide comprehensible guarantees and clear failure handling semantics. Certain failure scenarios can result in mirrored queues confirming messages too early, potentially resulting in a data loss.
Quorum Queues to the Rescue!
So what should we do? Enter Quorum Queues.
Quorum Queues are based on a consensus algorithm named Raft, and they are considered the next version of high availability queues.
🚨 RabbitMQ even says that Mirrored Queues will be removed in a future release! 🚨
At this point you’re probably saying to yourself: “You got me, I want to have quorum queues!”
Well, apparently they are not supported out of the box in celery (as of September 2021, update: May 2022).
If you follow the celery instructions and naively define a queue with type quorum, you’ll actually get an amqp.exceptions.AMQPNotImplementedError: Basic.consume: (540) NOT_IMPLEMENTED - queue 'add_queue' in vhost '/' does not support global qos 😵
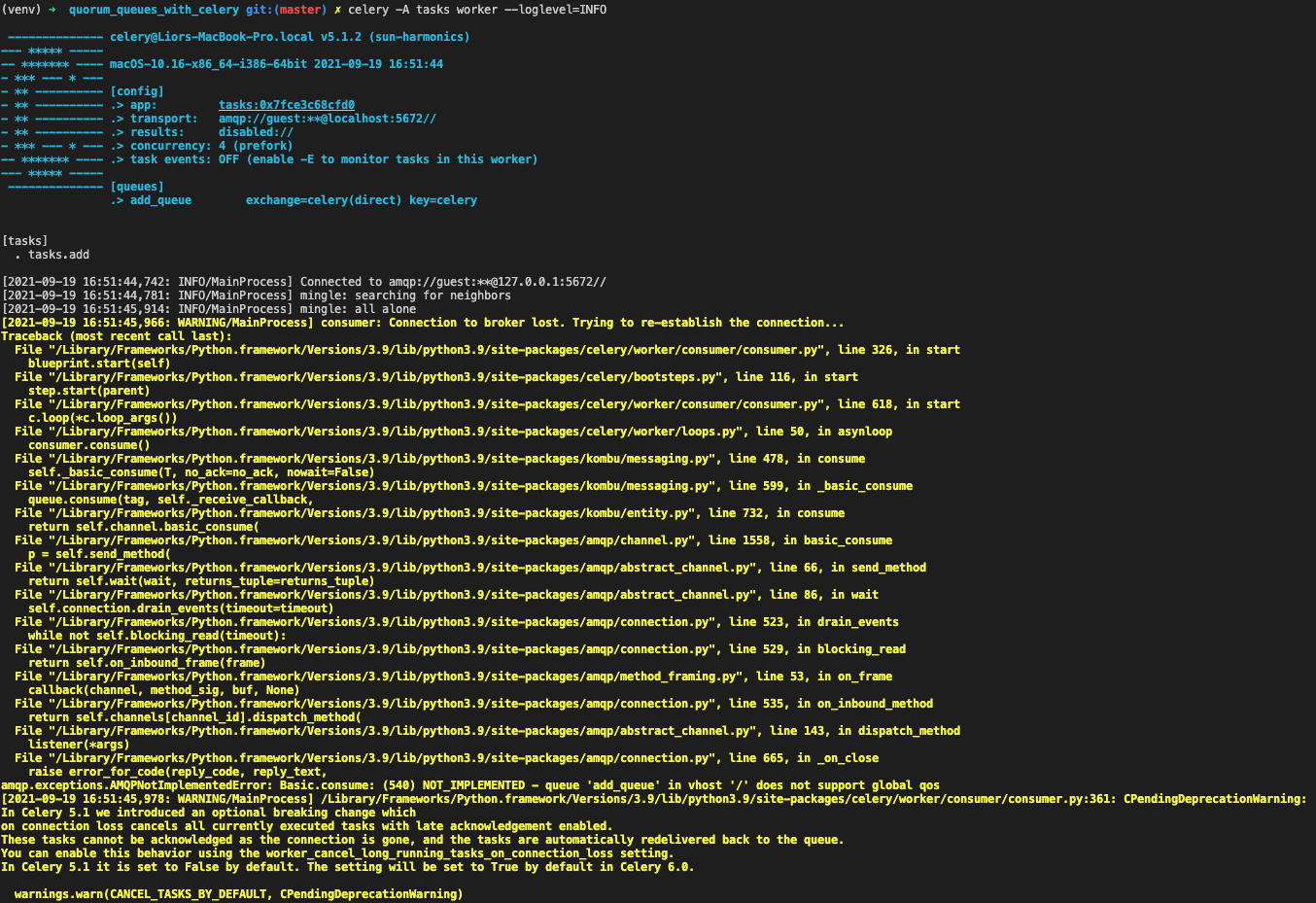
queue_arguments={"x-queue-type": "quorum"}This stems from the fact that celery sets a global QoS (in simple terms, this means that the message prefetch count is global for all the consumers of the queue).
The “Hack”
But… you can still use them.
By hooking into the bootsteps of the celery worker, you can force it to have a per-consumer QoS, in this manner:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class NoChannelGlobalQoS(bootsteps.StartStopStep):
requires = {'celery.worker.consumer.tasks:Tasks'} # Required for the step to be run after Tasks has been run
def start(self, c):
# In this context, `c` is the consumer (celery worker)
qos_global = False
# This is where we enforce per-client QoS, the rest is just copypaste from celery
# Note that we set to prefetching size to be 0, so the exact value of `c.initial_prefetch_count` is not important
c.connection.default_channel.basic_qos(
0, c.initial_prefetch_count, qos_global,
)
def set_prefetch_count(prefetch_count):
return c.task_consumer.qos(
prefetch_count=prefetch_count,
apply_global=qos_global,
)
c.qos = QoS(set_prefetch_count, c.initial_prefetch_count)
app.steps['consumer'].add(NoChannelGlobalQoS)
Inspired by this observation by @Asgavar, it is possible to run quorum queues in celery!
An example project can be found here.
Let me know in the comments if this worked for you! 🤠
UPDATE [01.05.2022]: Thanks to Ilai Shai for several refinements to the celery code.
Comments